| 训练AI玩贪吃蛇(强化学习与Q | 您所在的位置:网站首页 › 贪吃蛇 游戏规则 › 训练AI玩贪吃蛇(强化学习与Q |
训练AI玩贪吃蛇(强化学习与Q
|
欢迎加入我们卧虎藏龙的python讨论qq群:729683466 ●导 语 ● AI近些年发展很火 不但可以下围棋 还可以玩各种各样的游戏 国外有人构建AI模型 然后训练出了非常厉害的拳击手 相信有一天 AI和机器人结合 肯定能训练出比泰森还强的高手 今天我们看一个简单的AI项目 AI自动玩贪吃蛇 代码及相关资源获取 1:关注“python趣味爱好者”公众号,回复“AI玩贪吃蛇 ”获取源代码。 效果演示 游戏只训练了很短的时间,所以效果不太好,感兴趣的同学可以多训练几次。
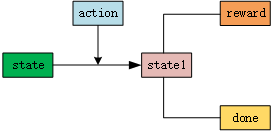
往期精选 sdpython游戏:小蜜蜂历险记(一) python小游戏之《小猫抓鱼》 🛠 开发工具 python3.10 第三方库:pygame,collections,enum 讲解部分 一:原理介绍 这里用到的核心知识是强化学习,这是一种无监督的算法,与有标签的监督学习不同,在深度学习中,监督学习的意思就是需要人工标注的正确答案,通过这些正确答案来训练神经网络,最终使神经网络可以准确模拟出下一步的操作。 但是在无监督学习中,并没有人告诉程序,你走的哪一步是正确的,哪一步是错误的。程序自动不断试错,如果撞到了墙壁或者尾巴直接死亡,吃到食物获得奖励。这样神经网络才知道哪些动作正确,哪些不正确。 二:Q-learning算法 在Q-learning算法自我训练的过程中,有5个比较重要的元素来评估当前状态的价值,首先是state,也就是当前的状态,对于贪吃蛇来说,这个状态很简单,就是蛇的位置,食物的位置,蛇移动方向等等。将这些信息组合在一起,形成一个向量,这就是当前状态,然后第二个元素就是蛇的选择action,一共4个方向,向前是无效的,向后是自杀,所以只有两个方向,向左向右(相对于蛇的移动方向来说)。这个选择就是action。随后,我们把state做出选择action后产生的新状态写作state1,这是第三个元素。如果state1是游戏结束(死亡),那么第四个元素done就是False,否则就是True。最后一个元素就是reward,也就是这个状态state1的奖励,如果吃到了食物就是奖励10分,否则就0分,如果死亡了,分数那就是-10分。 用一个图表示上述状态就是。
Q-learning核心公式如下:
在代码中实现公式如下: Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx]))用于评估每个状态的value,以训练神经网络 整个Q-learning的代码如下: class QTrainer: def __init__(self,model,lr,gamma): self.lr = lr self.gamma = gamma self.model = model self.optimer = optim.Adam(model.parameters(),lr = self.lr) self.criterion = nn.MSELoss() for i in self.model.parameters(): print(i.is_cuda) def train_step(self,state,action,reward,next_state,done): state = torch.tensor(state,dtype=torch.float) next_state = torch.tensor(next_state,dtype=torch.float) action = torch.tensor(action,dtype=torch.long) reward = torch.tensor(reward,dtype=torch.float) if(len(state.shape) == 1): # only one parameter to train , Hence convert to tuple of shape (1, x) #(1 , x) state = torch.unsqueeze(state,0) next_state = torch.unsqueeze(next_state,0) action = torch.unsqueeze(action,0) reward = torch.unsqueeze(reward,0) done = (done, ) # 1. Predicted Q value with current state pred = self.model(state) target = pred.clone() for idx in range(len(done)): Q_new = reward[idx] if not done[idx]: #Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx])).cuda() Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx])) target[idx][torch.argmax(action).item()] = Q_new # 2. Q_new = reward + gamma * max(next_predicted Qvalue) -> only do this if not done # pred.clone() # preds[argmax(action)] = Q_new self.optimer.zero_grad() loss = self.criterion(target,pred) loss.backward() self.optimer.step()三:神经网络 神经网络是深度学习的基本概念,这里不过多介绍,直接展示一下我们设计的神经网络代码,相信大家能看懂。 class Linear_QNet(nn.Module): def __init__(self,input_size,hidden_size,output_size): super().__init__() # self.linear1 = nn.Linear(input_size,hidden_size).cuda() # self.linear2 = nn.Linear(hidden_size,output_size).cuda() self.linear1 = nn.Linear(input_size,hidden_size) self.linear2 = nn.Linear(hidden_size,output_size) def forward(self, x): x = F.relu(self.linear1(x)) x = self.linear2(x) return x作者|齐 编辑|齐 感谢大家观看 有钱的老板可打赏一下小编哦 扫描二维码 关注我们 QQ群:729683466 ◰ 参考来源 代码来源:github |

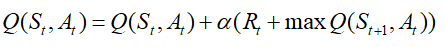
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |